PROJECT: Live Social SemanticsThe Live Social Semantics (LSS) project is the result of a collaboration between the SocioPatterns project and Harith Alani and Martin Szomszor of the TAGora project. In this project we investigate the requirements and consequences of the integration of data on social interactivity in the offline world, with social data, profile data, and semantic data from the online world. The scientific objectives are twofold:
We believe that the best way to learn about the right research questions is to actually design and build experimental systems that can be deployed at real-life social gatherings. The concrete type of social gathering we choose to investigate first were scientific conferences. We did so because as regular participants in scientific conferences ourselves, we should have a reasonably good idea of the needs, requirements and opportunities. We also expected participants of such conferences, and in particular conferences with computer science topics that are closely related to the project, to be more open to and willing to participate in the highly experimental system and services we envisioned to deploy. To attain the envisioned data integration and service platform, we had to deal with a number of technical and semantic challenges:
The following movie provides an introduction to the Live Social Semantics platform. A more detailed description is given on the remainder of this page. Introduction to Live Social Semantics DataMeshing online and offline social networksKnowledge of the online or offline social network separately serves as a substrate for constructing useful social services. However, the separate datasets generally capture only a facet of the broader social fabric. Meshing knowledge of the complementary online and offline social activities can be expected to greatly improve this potential. The degree at which this data can be integrated by the Live Social Semantics (LSS) system and consequently the level of services that can be offered, depends on the amount of identifying information the participants are willing to provide to the system. Each SocioPatterns badge is associated with an LSS profile, which is initially anonymous. By providing the necessary information, the participants can bind their profiles in online social systems to their LSS profile. This allows the system to access profile data and integrate friendship/fan/follower connections between known participants in the LSS graph. Making Use of Linked DataThe amount and variety of semantic data available on the web is continuously growing. The Linked Data initiative has been instrumental in this. Data from various conferences (e.g. ESWC, ISWC, WWW) has been consistently collected and published in recent years [1], and can be retrieved from sites such as data.semanticweb.org. This data has been merged with data from several publication databases (e.g. CiteSeer, DBLP) by the RKBExplorer system [2]. Based on basic profile data, which is either explicitly provided by the participant or retrieved from one of the provided online profiles, the LSS system attempts to retrieve relevant data from these linked data sources. The results are used to infer communities of practice (COP), which provide complementary knowledge about the scientific collaboration networks of the participants. Mining folksonomiesThe tags that people use on various Web 2.0 sites –for example to annotate their pictures on Flickr or their bookmarks in Delicious– tend to represent their personal interests [3]. Avid users are often active across several such sites, each of which solicits different aspects of a user’s interests. If these are brought together, a far richer understanding of a user’s interests can be obtained and subsequently used for superior personalisation, recommendation or awareness services [4]. Users often carry some of their tagging selections and patterns across different folksonomies [5]. Other social networking systems such as Facebook provide a more explicit means for users to defines their interests. Retrieving interests of conference attendees from multiple social sites, interests that might transcend the academic or scientific domain, should further contribute to the substrate for social services. To exercise this potential the LSS system generates Profiles of Interests (POI) for participants and integrates it in the LSS graph. SystemThe following diagram provides an overview of the Live Social Semantics (LSS) system.  A diagram that provides an overview of the Live Social Semantics system. A detailed description is provided in the text hereunder. Starting at the top-left of the LSS system diagram, we see the web-based systems from which data was obtained. This data is sourced and processed by the semantic extraction and inference technology developed by Harith Alani and Martin Szomszor and collaborators in the context of the TAGora project. The linked data sources were semanticweb.org and the RKBexplorer. From the former the system sourced data on the scientific collaboration network among participants by looking at academic publications and projects, while from the latter the communities of practice (COP) of the participants were obtained. The social networking and annotation systems were Facebook, Flickr, LastFM, Delicious, and Twitter (the latter for the third deployment only). From these the system sourced profile data, social network data (friends/fans/followers/etc), and annotation (tags) data. This data was obtained through available APIs (such as the Facebook graph API) or by means of screen scraping using the TAGora Extractor Daemon. All this data is either sourced in linked data form directly from the semantic web sources, or converted to a linked data representation via the Extractor Daemon. All data was represented using an agreed ontology and URI syntaxes, and stored and integrated in a high-performance triple store (JXT Triple Store, later Garlik 4store). The use of semantic repositories and formats made it relatively easy to automatically integrate heterogenous data from our various sources at run time, as well as provide one service endpoint that supports the collection and reasoning over the integrated data. The Profile Builder (center, top of diagram) processed the tagging data obtained from the triple store and links them to DBpedia URIs using the TAGora Sense Repository. Similarly, favourite music artists from LastFM were linked to DBpedia URIs using DBTune. From this the Profile Builder builds a list of potential interests, which the users can edit and expose to other participants. DBPedia was our choice lingua franca for representing participant’s interests. From the “real world” the system collected data on the face-to-face spatial proximity of the participants as a proxy observable for person-to-person non-technologically mediated interactions, henceforth called contacts, as well as the room-level location of the participants in the public conference areas. This dynamic data was collected by means of the SocioPatterns Monitoring Platform. This platform involved a locally installed server that collects and processes the data in real-time, and communicates via RDF/HTTP with the offsite triples store. The SocioPatterns data was injected in the triple store using a custom contact ontology to represent social interactions between individuals. The web interface allowed participants to manage their profile. After creating an LSS profile, the participant could associate their badge ID with their profile; provide basic profile information such as their name, affiliation and role in the conference; and link their profiles in online social systems with their LSS profile. All data collected through or shown in the web interface was stored in or obtained from the triple store. The web interface was implemented using Django and hosted on a remote server. For further details, please consult our publications listed at the bottom of this page. ServicesWe considered community building to be one of the principal objectives of a scientific conference, and pursued a number of opportunities where the Live Social Semantics system could help the organizers, speakers and attendees to better fulfill this objective. NetworkingThe LSS system sought to provide its users with a number of tools to facilitate their networking activities. The main aspects of networking activities in which we considered access to information to play a role were the identification of potential new contacts, and in extension of that, the procurement of background knowledge and potentially subject matter to facilitate the conversation during the initial interactions. The LSS system sought to contribute in two ways: the profiles of interest and the user focus visualization. We intentionally restricted these tools to be passive, to provide information only. We eschewed providing tools that actively facilitate communication with other participants as we were not prepared to risk the system to be perceived as the cause rather than the medium of uninvited contact initiations that are regarded as being too intrusive. Profiles of interestFriendships are often grounded on shared interests. Providing the ability to efficiently learn about other participants’ interests can thus be expected to enable a more effective identification of potential new friendships. Profiles of interest can be inferred from the participant’s tags on online social annotation systems such as Delicious and LastFM; the participant’s explicit likes on Facebook; and semantic data from sources such as DBpedia and DBTune (see the System section or the publications for more details). While it is in principle possible for a user to infer a person’s interests by accessing the same online resources, this is in practice a very time consuming exercise. The efficiency with which a computational system can retrieve and reason over vast amounts of data in order to automatically infer interests stands as a unequalled advantage. Even though the kind of reasoning these systems are able to perform are very simplistic compared to human cognitive capacities, the sheer amount of data points it can take into consideration, can, on very specific tasks such as this, largely make up for its relative lack of intelligence. Furthermore, by imposing the requirement for participants to explicitly expose, and potentially edit, the individual interests inferred for them by the system, we effectively introduced a filter that eliminates false positives (as well as embarrassing true positives), as such further improving the results with minor investment on the participants’ part. One could go one step further and make automated recommendations based on a systemwide comparison of the profiles of interest. We, however, refrained from going that far as we were wary to cross the fine line between augmenting social networking and biassing it. Closing of trianglesAnother auspicious approach for identifying potential new friendships is through the so-called closing of triangles. The underlying idea is that the potentiality for a friendship between a person and a friend of a friend of that person, is higher than on average. This approach cannot uncover potential connections between members of disparate communities like the profile matching approach. However, by regarding the actual friendships, this approach indirectly considers all actual shared interests, even those that are impossible to infer by the profile builder. Here too we refrained (for now) from inferring and giving recommendations, and rather choose to show the relevant data by means of the user focus visualization, which is described below. And while here too it is in principle possible for participants to browse the various online social networks themselves, the clear advantage of the visualization is that it provides a one-stop visualization of all relevant data in one integrated overview of one’s social neighborhood. Social activity logWhile the two previous tools support a very reasoned and targeted approach, LSS also sought to support a more serendipitous networking by simply providing logs and summaries of the social interactions of the participants, integrated with information from people’s social profiles of interest, scientific communities of practice, and their online social contacts. General comprehension of the communityBesides concrete tools for individual networking activity, we believe that community building also profits from a improved comprehension of the community in order the strengthen the sense of community. The spatial view visualization, which is described in more detail below, is one approach to contribute by simply showing an accurate overview of the current state of social activity at the conference. Other approaches are 1) to allow participants to explore each others’ interests in the web interface, or 2) to allow them to browse each others’ social contexts in the interactive user focus visualization, or 3) provide awareness of the presence of their COP members at the conference. Other examples of functionalities afforded by the available data are 1) providing an overview of talks given by friends or COP members, and 2) the ability to locate friends, colleagues, session chairs, organizers, etc. at the conference. VisualizationsTwo kinds of real-time visualisations were provided. The first, the spatial view, was publicly displayed on large screens in the main lobby area. The second, the user focus view, was integrated in the web interface. Both are dynamic visualisations driven by regular updates received through a TCP socket connection with the locally installed SocioPatterns server. Spatial viewThis visualization is based on the instantaneous face-to-face contact graph visualization used in previous deployments of the SocioPatterns Platform. While the main focus remained on the ongoing face-to-face contacts, we explored the potential of improving the visualization by also displaying aspects of the complementary social network data obtained from the online social systems or linked data sources. To optimize the contextual relevance of the shown complementary data, we decided not to show all connections in these networks, but only the projection of these graphs onto the real-time face-to-face contact graph, or in other words, from these complementary graphs only those edges were retained for which a parallel edge was present in the real-time contact graph.  Screenshot of dynamic Live Social Semantics instantaneous visualization, with inset of detail showing the various online social system icons that decorate the real-time face-to-face contact edges. Click image to view at full size. The resulting visualization represented each participant (wearing a badge) within range of the RFID readers as a labelled yellow discs or, when possible, the profile picture obtained from the corresponding Facebook or Twitter profile. The ongoing face-to-face contacts among these participants were represented by yellow edges drawn between the marks that represent the respective interlocutors. The thickness and opacity of these edges reflects the weight of the contact. These edges were decorated, where applicable, with small Facebook, Flickr, Delicious, lastFM or COP icons, marking the occurrence of that relationship in the respective complementary graph. Like in the previous instantaneous visualizations, the RFID readers were represented by labelled grey shapes, equiangularly laid out on a circumcentric oval. The participants’ shapes were positioned near or in between the readers’ marks they are closest to. This approach adds spatial structure to the contact graph representation. User focus viewThis visualization was based on the user focus visualization that we experimented with in the 25C3 deployment in Berlin. It focusses on the social neighbourhood of a particular participant. It shows 1) all participants with whom this central participant is currently having face-to-face contact, using yellow edges; 2) all participants with whom this central participant had face-to-face contact, using gray edges; and 3) all participants with whom the central participant is connected in one of the online social systems or whom are in his or her community of practice, using cyan edges decorated with small icons to indicate which kind of connections are present. The following figure shows a screenshot of the user focus view in which the central user is HAlani. At the time when this screenshot was taken, the central user participated in a three-way interaction with MMattsen and and an anonymous user with badge id 1103, as indicated by the yellow edges between their respective representations. The icons on two of these edges indicate that HAlani and user 1103 are friends on Facebook, while MMattsen en user 1103 are connected in Delicious. HAlani furthermore has had significant contact at the conference with CCattuto, as indicated by the strong grey edge connected their representations, and is connected in one or several online social systems with both WVandenBr and MSzomszor. And finally the various social connections between CCattuto, WVandenBr and MSzomszor are also shown.  Screenshot of Live Social Semantics user focus view. Click image to view at full size. When the system detected changes in the ongoing face-to-face contacts, learned about new connections in the online social networks, or inferred additional community of practice links, the visualization was dynamically updated accordingly. The visualization was provided as a Adobe Flash application embedded in the Live Social Semantics web interface and accessible to the participants who created a LSS profile. While initially focussed on themselves, the participants could interactively focus on other users. The following image shows the interface that pops up when clicking a participant’s representation.  Screenshot of Live Social Semantics user focus visualization, with detail showing the interface that pops up when clicking a participant's representation. This interface enables the user to learn more about the participant, to move the focus to this participant, to visit his or her website or online profile when given. PrivacyThe participation in the Live Social Semantics experiment was purely opt-in. The participants had the choice to wear a SocioPatterns badge and thus participate at the level of the collection of data on the face-to-face contacts; they had the choice to create an LSS profile or not; they could choose whether or not to link this profile with their profile in the online social systems; and they had to actively select which interests inferred by the system they wanted to expose to the other participants and could edit them before doing so. Nevertheless we additionally sought permission on paper from all participants for collecting and using their data. A Terms & Conditions form was prepared which explained what data was going to be collected, how it was going to be used, and for how long. Users were shown how the RFID badges are used, and the geographical limits of where their face-to-face contacts could be detected. We also took various measures in order to secure the collection and storage of the data. All data from the RFID devices was encrypted before being transmitted to the server to ensure that, even when it was intercepted, it could only be processed by our systems. All gathered data was stored in private triplestores, only accessible to the developers of this application. People responded differently to the prospect of being a subject of the data collection and integration functionality of the Live Social Semantics system. Some participants were only prepared to take part if the data was anonymised, while other asked for the data to be kept without any anonymisation, to be stored for reuse in coming events, and even to be published so they could link to their profiles and contacts logs from their websites and blogs. Sharing data with other participants was not an issue for most participants as a majority was apparently happy to share their social networking accounts. We also received several accounts of conference attendees who initially did not want to participate due to privacy concerns, but became eager to do so after they observed the system at work and the functionality it offered to their friends and colleagues who did participate. At ESWC ’09, users were given two options in the Terms & Conditions form: (a) to permit their data to be retained in an anonymized form, or (b) to destroy their data after the conference. 61% of the participants were happy for their data to be kept, while 39% requested the destruction of their data. This approach, however, introduced a number of inconsistencies and ambiguities. Many users expressed their interest in obtaining their data after the conference. However, the anonymisation actually precludes that. Other issues, such as whether a participant holds the right to access information on recorded contacts with participants that choose to have their data fully removed, pointed to the need to reconsider the privacy and data retention policies for future deployments. We explored other approaches and discussed these issues with specialists, but we concluded that, for the time being, there is no broadly accepted approach on how to best deal with the privacy related aspects of social data driven services such as the Live Social Semantics system. The ever more far-reaching automated data collection and integration functionality afforded by the rapid evolution of sensor and computation technology creates novel opportunities for social services and tools that push the envelope. With it comes the need for society at large to come up with a cultural framework in which to approach the entailed privacy issues, as well as the responsibility for innovators to be careful and prudent. Acknowledgements
Deployments associated with this project:Publications associated with this project:
References
|
NEWSNew data sets published: co-presence and face-to-face contactsThrough a publication in EPJ Data Science, we have released several new data sets of different types. These datasets can be found on Zenodo. On the one hand, we have released new temporally resolved data on face-to-face interactions collected in
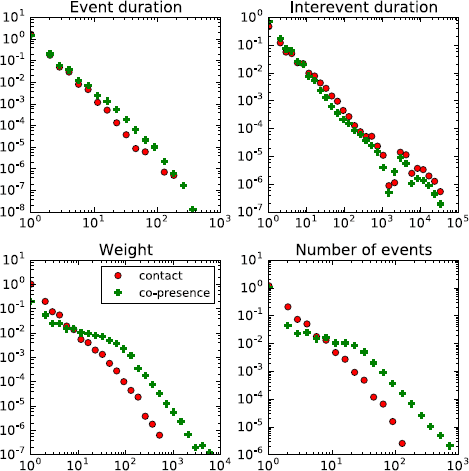
In addition, we release data sets describing the temporally resolved co-location of individuals, where co-location of two individuals at time t means that the same exact set of readers have received signals from both individuals at time t. Data can be found on our website or on Zenodo. Obviously, the co-location data corresponds to a coarser spatial resolution than the face-to-face data, and we have compared the corresponding data in terms of structure and when used in data-driven simulations of disease propagation models in our paper.
SocioPatterns: measuring animal proximity networksAfter so many measurements concerning humans in different contexts (which we will continue measuring), SocioPatterns has partnered with different institutions to measure proximity networks of animals, ranging from free-roaming dogs to sheep and cows. The goals of the studies range from the study of social networks of animals to the development of better models of disease transmission in animal groups.
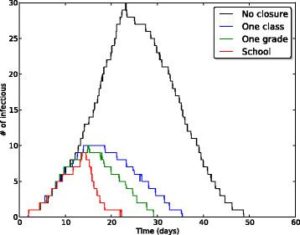
School closures to mitigate influenza spread: two studies based on SocioPatterns dataIn order to fight and mitigate emerging epidemics, non-pharmaceutical interventions can become necessary. Among these, school closure is typically regarded as a viable mitigation strategy: children indeed are known to play an important role in the propagation of infectious diseases, due to their high rate of contacts at school. School closure is however a costly measure whose applicability remains uncertain and whose implementation should carefully be weighed on the basis of cost-benefit considerations. In two successive studies published in BMC Infectious Diseases, we have used high resolution data on the contact patterns of children that we collected in a primary school,(i) to define and investigate alternative, less costly mitigation measures such as the targeted and reactive closure of single classes whenever symptomatic children are detected, at the scale of a single school and (ii) to evaluate the effectiveness of several such gradual reactive school closure strategies at the scale of entire municipalities. Our results highlight a potential beneficial effect of reactive gradual school closure policies in mitigating influenza spread. Moreover, the suggested strategies are solely based on routinely collected and easily accessible data (such as student absenteeism irrespective) and thus they appear to be applicable in real world situations. References: Mitigation of infectious disease at school: targeted class closure vs school closure
SUPPORTED BY |
|
|